本文最后更新于:星期四, 一月 14日 2021, 4:14 凌晨
为什么写本文?
在工业级的开源对话系统系统中,RASA 是不二之选。
基于 RASA 的简单的对话系统文章有很多,本文就不在赘述。但是基于 RASA 语音对话的文章很少。
所以,本文主要是搭建一个基于 RASA 的语音 对话系统。
基本资料参考于 这篇文章。
简单的说就是踩坑避险记。
你能学到什么?
RASA的一些相关知识
- 如何在
RASA中自定义channel
- 如何在
- 如何使用
deepspeech实现STT(语音转文字)
- 如何使用
- 如何使用
TTS(文字转语音)
- 如何使用
最终呈现是什么?
看看这里:
一些基础介绍
实现语音助手需要什么
再来个具象一点的图
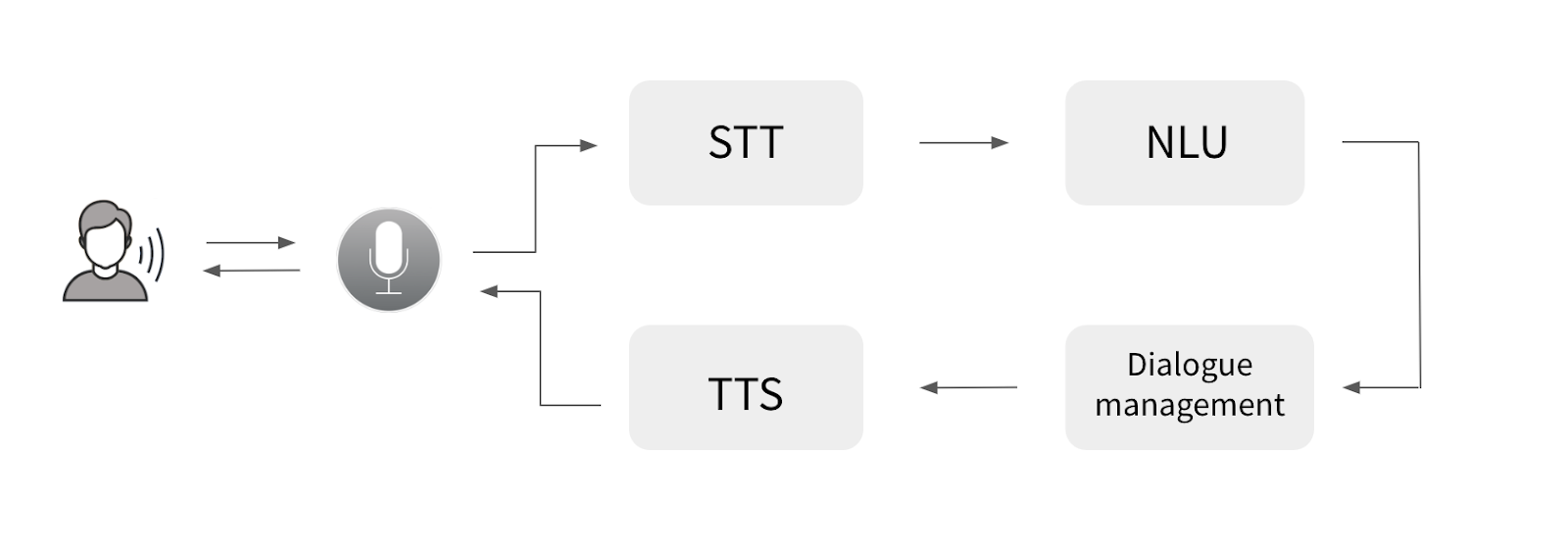
从上图我们可以看出,我们核心要解决的即是 SST、对话模块以及TTS
对话模块,我们有了 rasa 来作为实现。
其余两个我们选择开源工具来实现。
STTTTS
我们思考一下够了吗? 当然不够!
语音从哪里来?到哪里去?
没错,我们还少一个 UI,作为与用户交互的接口。
这里我们选用: rasa-voice-interface
有了这4个神器,基础版本的需求我们应该能满足了。我们来看一下我们的架构:
注意:
右边rasa的图为1.x版本的结构,2.x应该为NLU(自然语言理解)和DM(对话管理)
合起来就能实现整个对话。
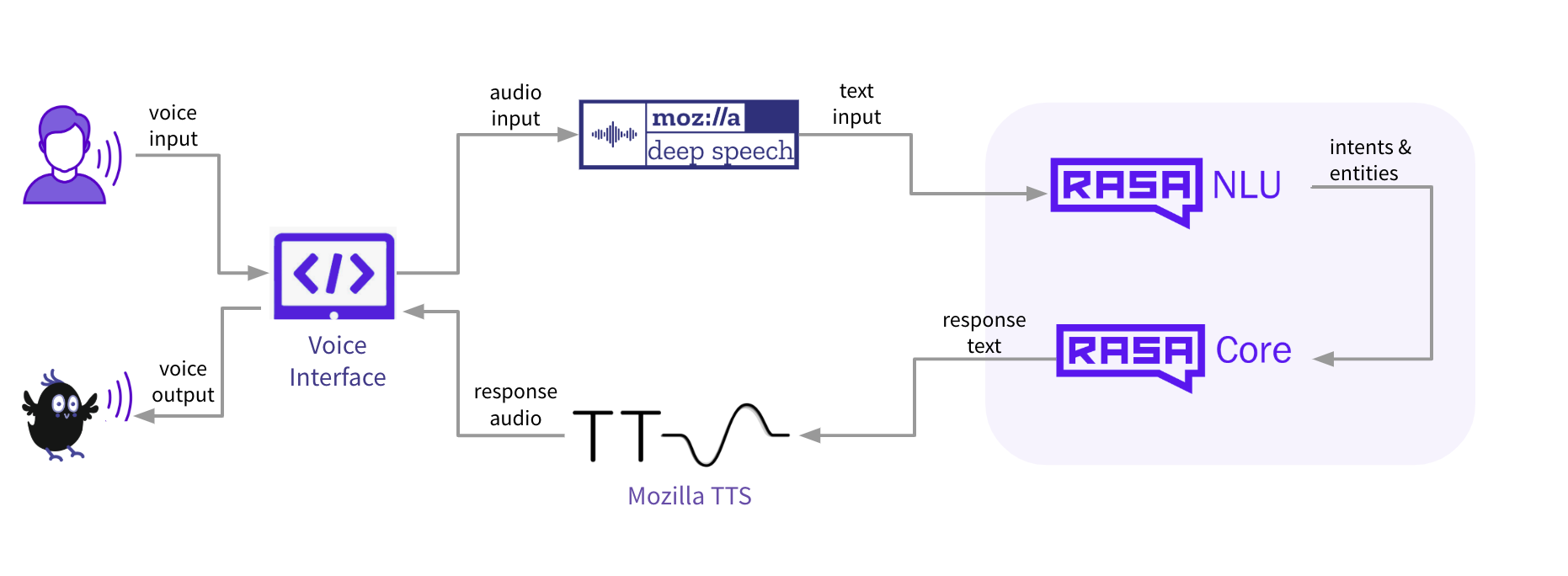
好了,这就是我们所需要的全部内容,看起来也不太复杂对吧。(嗯!的确不太复杂。)
我们应该思考一些什么
各部分如何连接?
拆成 4 部分后,其实我们的每一部分都可以替换,
比如:
STT替换为接口请求服务(CRUD大法好)TTS替换为借口请求服务(CRUD大法好得不得了)RASA替换为Google Dialogflow、Wit.ai、Microsoft LUIS、IBM Watson等
但是 UI 的替换稍微麻烦一些,那我们就假定 UI 的逻辑是不变的,看看我们应该怎么办。
我们先想一下各部分的输入输出:
UI:graph LR; 输入 --- id1>语音]; 输出 --- id1;都是
语音的输入输出,那么要么是文件传输,要么是源数据传输。
从UI的源码中我们可以看出,用户输入语音后,通过socket传输base64编码的语音数据,传给5005端口。输出语音通过一个连接下载语音,然后播放。STT:graph LR; 输入 --- id1>语音]; 输出 --- id2>文本];TTS:graph LR; 输入 --- id1>文本]; 输出 --- id2>语音];RASA:graph LR; 输入 --- id1>文本]; 输出 --- id1;通过以上的输入输出,我们可以看出,我们主要需要实现一个中间件,实现各部分数据的流转。
这个中间件的功能主要是:
实现文本语音的互转,并控制文本数据在RASA中流转。
就像这样:graph LR; 语音-- middleware --> rasa; rasa -- middleware --> 语音;
于是,我们选择的目标变成了制作一个控制 语音文本 转换的 middleware 。
制作 middleware
怎么做?怎么结合?说那么干嘛,直接做呀。
别急,我们看看 RASA 的文档。
…… 经过短暂的文档查阅
好家伙,搜到 voice 了。
看看源码(源码阅读中…原来如此原来如此…, OutputChannel 获得, InputChanel 获得)。
从源码中,我们发现虽然只有 发送 audio 的功能是我们需要的功能的一部分,但是至少我们知道了 Rasa 中有一个 Channel Conncetor 的东西,能帮我们进行输入输出的调整,连接到不同的地方(相当于匹配不同的 UI, 例如: Slack、Facebook ...)。
于是,我们新的目标,有了!
制作我们自己的 Channel。
开始制作 Channel
选择基础 Channel
目前有两种 Channel 可以选择, Rest Channel 以及 WebSocket Channel
这里我们选择 WebSocket Channel (因为 UI 的接口是 WebSocket)
编写代码
编写 voice_connector.py 。
等等,太快了。我们先看一下整体结构,整理一下。根据 Channel 的示例。
我们需要两个类 VoiceInput, VoiceOutput, 分别对应 Channel 的 输入和输出。
VoiceInput 中需要实现:
- 接收语音数据
STT
VoiceOutput 中需要实现:
TTS- 发送语音数据
开始 VoiceInput
我们继承现有的 SocketIOInput,重写主要的部分,blueprint 方法,核心代码如下:
class VoiceInput(SocketIOInput):
def blueprint(
self, on_new_message: Callable[[UserMessage], Awaitable[Any]]
) -> Blueprint:
# Workaround so that socketio works with requests from other origins.
# https://github.com/miguelgrinberg/python-socketio/issues/205#issuecomment-493769183
sio = AsyncServer(async_mode="sanic", cors_allowed_origins="*")
socketio_webhook = SocketBlueprint(
sio, self.socketio_path, "socketio_webhook", __name__
)
self.sio = sio
--- skip --
@sio.on(self.user_message_evt, namespace=self.namespace)
async def handle_message(sid: Text, data: Dict) -> Any:
"""处理收到的客户端数据"""
output_channel = VoiceOutput(sio, self.bot_message_evt) # 初始化 Output
message = data["message"]
if message == "/get_started":
message = data["message"]
else:
"处理发送过来的语音数据"
bytes_data = base64.b64decode(message.split(",", maxsplit=1)[-1]) # 解码 base64 获取语音元数据
audio, fs = librosa.load(
BytesIO(bytes_data), sr=None, dtype="int16", mono=False
) # 获取声波数据
print("获取音频信息成功")
message = ds.predict_to_string(audio, fs) # STT
print(f"预测输出为: {message}")
await sio.emit(
self.user_message_evt, {"text": message}, room=sid
) # 文本发给前端,用作显示
message = UserMessage(
message, output_channel, sid, input_channel=self.name()
)
await on_new_message(message)
return socketio_webhook
代码也比较简单,模板其实没有变化,主要是 数据的处理逻辑发生改变。
需要注意的点:
self.user_message_evt这个event会执行handle_message方法。self.user_message_evt目前使用的默认值。- 执行
await on_new_message(message)的时候,就会执行RASA的NLU以及DM最终获得 一个输出的message, 这个message的格式可以自定义的。 sio = AsyncServer(async_mode="sanic", cors_allowed_origins="*"),这里cors_allowed_origins这样方便一些,否则跨域。
开始 VoiceOutput
同样,我们继承现有的 SocketIOOutput,重写主要的部分,send_text_message 方法,核心代码如下:
class VoiceOutput(SocketIOOutput):
async def send_text_message(
self, recipient_id: Text, text: Text, **kwargs: Any
) -> None:
"""Send a message through this channel."""
print("开始发送信息")
await self._send_audio_message(socket_id=recipient_id, response={"text": text})
async def _send_audio_message(self, socket_id: str, response: Any) -> None:
"""Sends a message to the recipient using the bot event."""
ts = time.time()
out_file_name = str(ts) + ".wav"
link = self.FILE_SERVER + out_file_name
tts_run(text=response["text"], file_name=out_file_name) # TTS 生成语音文件
await self._send_message(
response={"text": response["text"], "link": link}, socket_id=socket_id
) # 发送给前端
VoiceOutput 就更简单了。
需要注意的是:
- 这里我们重写
send_text_message方法,因为我们的机器人返回的为text的格式 {"text": response["text"], "link": link}这个为固定格式,前端从link地址下载 音频文件并播放。SARA 机器人的准备
这里我们使用官方的rasa-demo机器人做演示,其他机器人同理。
官方教程1. 安装
git clone https://github.com/RasaHQ/rasa-demo.git --depth 1 cd rasa-demo pip install -r requirements.txt pip install -e .2. 训练模型
rasa train --augmentation 0 # 加速训练
3. 更改 channel
创建 credentials.yml
内容如下:
utils.voice_connector.VoiceInput:
bot_message_evt: bot_uttered
session_persistence: true
user_message_evt: user_utteredutils.voice_connector.VoiceInput 为放我们编写的 channel 的地方,需制定到 Input 的 class。utils 为文件夹名字。
4. 运行(不是现在)
ducklingdocker run -p 8000:8000 rasa/duckling
action serverrasa run actions --actions actions.actions
rasa apirasa run --enable-api -p 5005
但是我们可以体验一下,运行前两个服务后:rasa shell --debug
本地启动 rasa,我们就可以开始和机器人对话了。
其余剩余的部分
剩下部分比较简单,替代性比较强,我就简单过一下了。
STT
1. 安装及模型下载
# Install DeepSpeech
pip3 install deepspeech
# Download pre-trained English model files
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.pbmm
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.scorer2. 编写 STT 部分
deepspeech.py 使用起来相当简单。
from deepspeech import Model
class DeepSpeechModel:
def __init__(self):
self.ds = self._load_model()
@staticmethod
def _load_model():
ds = Model("deepspeech-0.9.3-models.pbmm")
ds.enableExternalScorer("deepspeech-0.9.3-models.scorer")
return ds
def predict_to_string(self, audio, fs) -> str:
return self._metadata_to_string(
self.ds.sttWithMetadata(audio, fs).transcripts[0]
)
@staticmethod
def _metadata_to_string(metadata):
return "".join(token.text for token in metadata.tokens)我们的 ds 有了。
TTS
1. 安装及模型下载
参考教程
使用到的模型:
curl -LO https://drive.google.com/uc?id=1dntzjWFg7ufWaTaFy80nRz-Tu02xWZos tts_model.pth.tar
curl -LO https://drive.google.com/uc?id=18CQ6G6tBEOfvCHlPqP8EBI4xWbrr9dBc config.json
curl -LO https://drive.google.com/uc?id=1Ty5DZdOc0F7OTGj9oJThYbL5iVu_2G0K vocoder_model.pth.tar
curl -LO https://drive.google.com/uc?id=1Rd0R_nRCrbjEdpOwq6XwZAktvugiBvmu config_vocoder.json
curl -LO https://drive.google.com/uc?id=11oY3Tv0kQtxK_JPgxrfesa99maVXHNxU scale_stats.npy安装 tts:
sudo apt-get install espeak
git clone https://github.com/mozilla/TTS.git
git checkout b1935c97
pip install -r requirements.txt
python setup.py install2. 编写代码
tts.py:
import time
from functools import partial
import torch
import wavio
from TTS.utils.audio import AudioProcessor
from TTS.utils.generic_utils import setup_model
from TTS.utils.io import load_config
from TTS.utils.synthesis import synthesis
from TTS.utils.text.symbols import phonemes, symbols
from TTS.vocoder.utils.generic_utils import setup_generator
# runtime settings
use_cuda = False
# model paths
BASE_DIR = "./"
TTS_MODEL = BASE_DIR + "tts_model.pth.tar"
TTS_CONFIG = BASE_DIR + "config.json"
VOCODER_MODEL = BASE_DIR + "vocoder_model.pth.tar"
VOCODER_CONFIG = BASE_DIR + "config_vocoder.json"
# 读取配置文件
TTS_CONFIG = load_config(TTS_CONFIG)
VOCODER_CONFIG = load_config(VOCODER_CONFIG)
# 加载 audio processor
ap = AudioProcessor(**TTS_CONFIG.audio)
# 加载 TTS MODEL
# multi speaker
speaker_id = None
speakers = []
# load the model
num_chars = len(phonemes) if TTS_CONFIG.use_phonemes else len(symbols)
model = setup_model(num_chars, len(speakers), TTS_CONFIG)
# load model state
cp = torch.load(TTS_MODEL, map_location=torch.device("cpu"))
# load the model
model.load_state_dict(cp["model"])
if use_cuda:
model.cuda()
model.eval()
# set model stepsize
if "r" in cp:
model.decoder.set_r(cp["r"])
# LOAD VOCODER MODEL
vocoder_model = setup_generator(VOCODER_CONFIG)
vocoder_model.load_state_dict(torch.load(VOCODER_MODEL, map_location="cpu")["model"])
vocoder_model.remove_weight_norm()
vocoder_model.inference_padding = 0
ap_vocoder = AudioProcessor(**VOCODER_CONFIG["audio"])
if use_cuda:
vocoder_model.cuda()
vocoder_model.eval()
def tts(model, text, file_name, CONFIG, use_cuda, ap, use_gl):
t_1 = time.time()
waveform, alignment, mel_spec, mel_postnet_spec, stop_tokens, inputs = synthesis(
model,
text,
CONFIG,
use_cuda,
ap,
truncated=False,
enable_eos_bos_chars=CONFIG.enable_eos_bos_chars,
)
if not use_gl:
waveform = vocoder_model.inference(
torch.FloatTensor(mel_postnet_spec.T).unsqueeze(0)
)
waveform = waveform.flatten()
if use_cuda:
waveform = waveform.cpu()
waveform = waveform.numpy()
rtf = (time.time() - t_1) / (len(waveform) / ap.sample_rate)
tps = (time.time() - t_1) / len(waveform)
print(waveform.shape)
print(" > Run-time: {}".format(time.time() - t_1))
print(" > Real-time factor: {}".format(rtf))
print(" > Time per step: {}".format(tps))
wavio.write(file_name, waveform, CONFIG.audio["sample_rate"], sampwidth=2) # 将 wav 写入文件
return alignment, mel_postnet_spec, stop_tokens, waveform
tts_run = partial(
tts, model=model, CONFIG=TTS_CONFIG, use_cuda=use_cuda, ap=ap, use_gl=False
)
if __name__ == "__main__":
sentence = "Bill got in the habit of asking himself “Is that thought true?” and if he wasn’t absolutely certain it was, he just let it go."
file_name = "myfile.wav"
align, spec, stop_tokens, wav = tts(
model, sentence, file_name, TTS_CONFIG, use_cuda, ap, use_gl=False
)
这样我们的 tts_run 也有了。 拼图就凑齐了。
UI 服务
1. 安装
git clone https://github.com/RasaHQ/rasa-voice-interface.git --depth 1
cd rasa-voice-interface
npm install2. 运行
npm run serve成功启动时的界面:
和 rasa 连接成功时的界面:
pint:
点击 start 之后,会自动完成音频上传,不需要再做点击。
还差一个,文件服务器
这里我们使用最简单的,注意,需要在 rasa-demo 文件夹的根目录运行。python3 -m http.server 8888
这样,我们所有的东西都有了。可以运行 rasa 部分的代码了~
总结
RASA 总结
- 在对于仅需处理输入输出的时候,利用
channel实现是最方便且最合理的。 rasa core已是过去式。channel目前基于sanic,能实现rest或者websocket。
服务总结
上面为所有的代码,以及模块的总结。但是,缺少一个服务间的调用,我们补一下。
先梳理一下,我们用到的服务。
duckling文本提取action serverrasa自定义action的实现rasa serverrasa本身的服务ui server前端UI服务http.server文件下载服务
服务调用关系如下:
用到的三方库的总结
waviowav文件的读写TTS的相关操作librosa文件数据转音频波socketiosocket serverdeepspeechSTT
所有的代码
代码仓库:
点击这里查看
主要是 utils 以及 compoments 的代码。
参考资料:
用 mozilla 工具和 rasa 构建语音助手(好看的图也引用的这里的(留下不学无术的泪水))
TTS
DeepSpeech
rasa voice ui